

Agile estimation is similar to how your car calculates your range on a tank of gas.
I obsess on watching the mileage my car gets. Every time I fill the tank I note how far I traveled on the last tank, and then I try to break that record with my new tank of gas.
As I have experimented with trying to get more from a tank of gas I have learned one key thing: The only part of the equation that is a constant is how many gallons of gas my tank can hold. How far I get on a tank of gas can very significantly depending on the kind of trips I go on.
For instance, if I strictly take my daughter to school via the freeway, I get really good mileage, but it is a 15 mile trip each way.
If I make a trip to the grocery store it is only 2 miles each way, but it is in the city and I have several stops and delays on the 2 mile journey. I burn a lot of gas sitting at redlights.
If I go to the airport it is about 10 miles, and also on the freeway without any stops.
I started watching my gas gauge and miles remaining after each trip. After a while I was able to identify patterns and categorize my trips into the impact they had on my tank of gas. Chart 1 shows the impact by trip type.
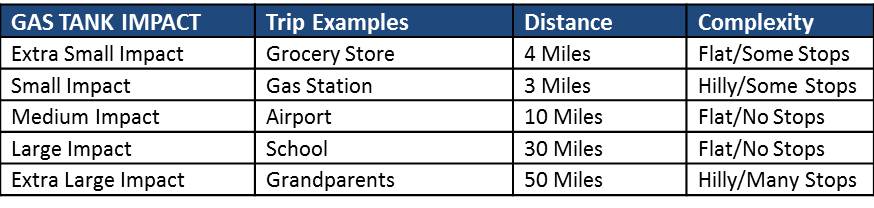
Chart 1 – How different trip types affect the amount of gas left in the tank.
After I identified the patterns, I started wondering if I could assign a weight to each type of trip. The weight would tell me the impact each trip had on my tank based on a weighted scale.
To do this, I decided to establish trip points. I would rate each trip with a weight that correlated to its impact to my tank of gas, and it’s relative size to the other trips. Chart 2 shows the system I came up with. (note that trip points are not directly correlated to miles traveled)

Chart 2 – Trip distance and complexity has a direct correlation to how much gas is used in my tank.
If you review chart 2, you can see that I believe a gas station trip hits my gas tank twice as hard as a trip to the grocery store, and a trip to the airport hits my gas tank twice as hard as going to the gas station, and so on.

My gas tank has fixed capacity, and that fixed capacity can support a limited amount of trips. How many trips is determined by trip distance and complexity.
Using this scale I created, I started measuring how many total trip points I was getting per tank of gas. After running through approximately 3 tanks of gas, I saw that I averaged 40 trip points per tank. The types of trips I did could vary, but consistently I saw that I was out of gas when I was around 40 trip points. In essence, a tank of gas was worth 40 trip points.
Using this information, I decided to forecast how many tanks of gas I would go through based on the trips I anticipated taking in the future. I created a diagram that shows how many tanks of gas I will need. Note that each trip has its estimated trip points listed to the left. See the diagram below.

Based on how many trip points I average per tank, I can forecast how many tanks are needed for all of my forecasted trips.
When I was done, I could see that I would need 4 tanks of gas for my forecasted trips.
So how could we correlate this approach to software project estimation?
First, in software development, our “trips” are user stories. And similar to the process we used on trips, we have the team look at each user story and determine its impact to a sprint. In software development, a sprint is our “tank of gas”. Let’s look at an example.
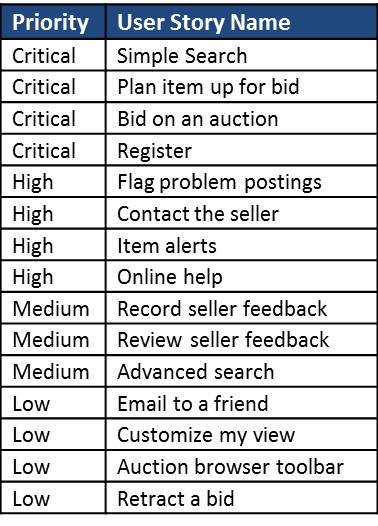
List 1 – A list of user stories for our project. How many tanks of labor (sprints) will we need to deliver them?
If we were building an online auction system, our list of user stories might look like the stories displayed in list 1.
And similar to our trips, each story could be sized. We size trips by distance and trip complexity (number of stops, terrain).
We size stories by the amount of code we expect to write and test, and how complex each story is (does it requires an interface? Have we ever written this type of code before?).
Table 1 below shows how a team could have went through and sized our list of stories for a project, based on how much coding and testing the story will need, plus the complexity of the story. The team discusses each story and based on their perception of coding/testing size, and how complex the story is, they establish story point values for each story.
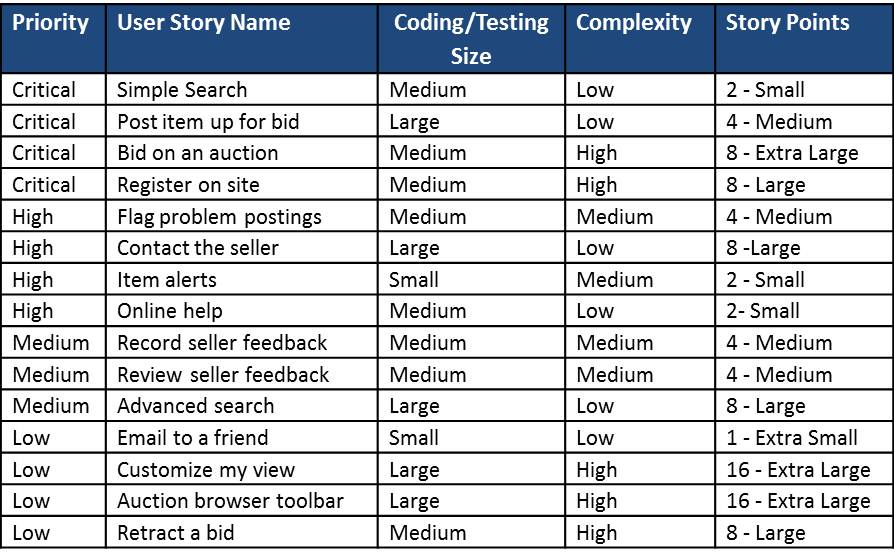
Table 1 – A list of user stories (backlog) is rated for coding/testing size and complexity.
Story point values are our estimates for how much impact each story will have on a sprint. So once we know the size of our stories, we need to know how many stories we can get from a tank of gas. For software teams a tank of gas is a sprint.
In our example, we would ask the team to go through a few sprints so we can determine how many story points they would average per sprint.
A team does this by typically guessing, usually a quick discussion, of how many stories they think can complete in a sprint, and they do the sprint to see how many they can actually complete. After a few sprints they usually have a good average they can use for future planning. In Agile terms we call this average throughput per sprint velocity.
For the purposes of this article, we will assume this team has worked together before, and they know how many story points they average as a group. For our example, we will say they usually average 24 story points completed in a sprint. So the team plans each sprint, so that it holds no more than 24 story points. They do agree to make an exception in sprint 3, and allow 25 story points to be assigned to that sprint. You can see their plan in the diagram below.
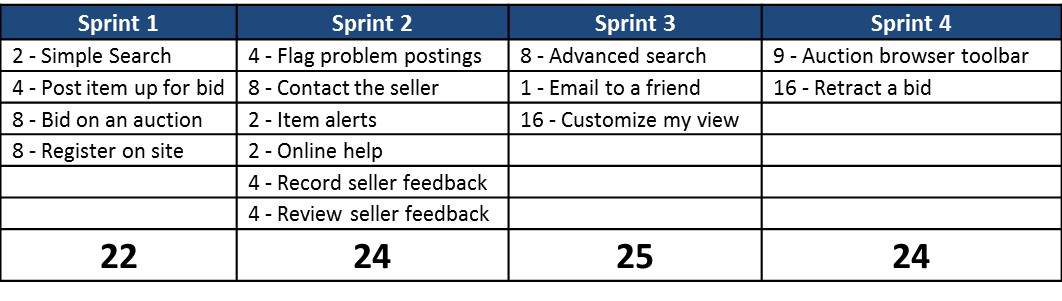
Release Plan Diagram – Based on how many story points they deliver in the average sprint, the team forecasts how many sprints will be needed for all of the stories in the backlog.
When teams assign stories to sprints, the Agile term is called creating a release plan.
Hopefully this example made it easier for you to understand how high level, relative estimation works in Agile projects. Feel free to drop me an email or leave comments if you have a question.
Notes:
- On an actual project we would probably use the Fibonacci sequence for our story point scale.
- On a real project we may have a rule that any story larger than 8 points must be broken down into smaller stories.
- Agile story point estimation is dependent on constants. Just as your trip computer does not expect the size of your gas tank to ever change, estimating story point requires that your team size and sprint length stay the same. If you change either item you must run a few sprints again to reset your baseline for story points you usually complete in a sprint.